Grundlagen der Convolutional Neural Networks: Ein schneller Einstieg in die Basics
Convolutional Neural Networks (CNNs) sind eine der grundlegendsten und leistungsstärksten Methoden in der modernen Computer Vision. Sie ermöglichen es Computern, spezifische Objekte in zweidimensionalen Bildern zu erkennen und haben Anwendungen in Bereichen wie Bildklassifizierung, Objekterkennung und Gesichtserkennung revolutioniert. In diesem Artikel werden wir die grundlegenden Konzepte eines CNNs kennenlernen und anhand eines einfachen Beispiels demonstrieren, wie man ein eigenes CNN erstellen kann.
In diesem Artikel werden die grundlegenden Konzepte eines Convolutional Neural Network (CNN) anhand eines einfachen Beispiels erläutert. Zunächst erhälst Du einen Überblick über den gesamten Prozess – vom Einlesen des Bildes über alle notwendigen Schichten bis hin zum finalen Ergebnis. Nachdem die Grundlagen besprochen sind, wird ein einfaches Python-Skript vorgestellt, das TensorFlow und Keras verwendet, um ein simples CNN zu demonstrieren. Dieses Skript kannst Du anschließend selbst ausprobieren und nach Ihren eigenen Bedürfnissen anpassen.
CNNs werden hauptsächlich in der Computer Vision eingesetzt, um spezifische Objekte in zweidimensionalen Bildern zu erkennen. Um eine genaue Prognose zu erzielen, durchlaufen die Eingabedaten mehrere sogenannte "Hidden Layers", bevor das endgültige Ergebnis ausgegeben wird. Zur Veranschaulichung wird im Detail erklärt, wie ein handgeschriebener Buchstabe, beispielsweise "D", erkannt wird. Parallel dazu wird der entsprechende Python-Code entwickelt, sodass die Theorie unmittelbar in die Praxis umgesetzt werden kann.
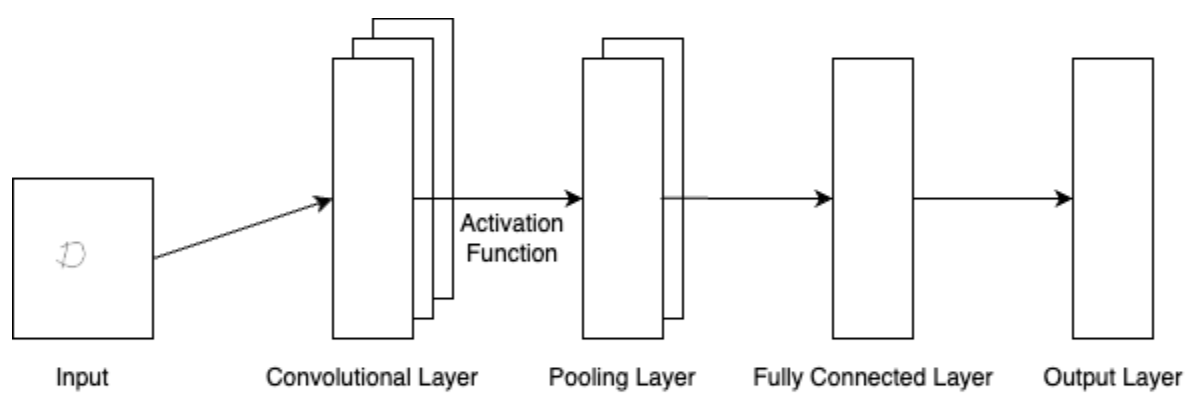 Abbildung 1: Skizze CNN Prozess
Abbildung 1: Skizze CNN ProzessWas du oben siehst, ist eine Skizze der Prozesse, die dieses grundlegende CNN durchläuft. Lass uns diese genauer betrachten:
Input: Zunächst benötigt das Netzwerk Daten, im Fall eines CNNs ein Bild. Nehmen wir also an, wir haben einen einfachen, handgeschriebenen Buchstaben „D“. Damit ein CNN ein Bild interpretieren kann, muss es eine bestimmte Struktur haben. In diesem Fall wird das Bild als 3D-Array mit Dimensionen entsprechend der Höhe, Breite und der Anzahl der Farbkanäle (z.B. 3 Kanäle für RGB-Bilder) dargestellt. Die Pixelwerte werden normalerweise auf einen Bereich von [0,1] oder [-1,1] normalisiert, bevor sie dem Netzwerk zugeführt werden. Angenommen, unser graustufiger Buchstabe „D“ hat eine Größe von 28x28 Pixeln, dann wäre die Eingabe ein 3D-Array mit den Dimensionen 28 (Höhe) x 28 (Breite) x 1 (Farbkanal). Die ursprünglich im Bereich von 0 (schwarz) bis 255 (weiß) liegenden Pixelwerte werden normalisiert, indem jeder Pixelwert durch 255 geteilt wird, sodass sie im Bereich von [0,1] liegen. Gehen wir nun weiter zum Convolutional Layer.
Convolutional Layer: Nach der Verarbeitung der Eingabe wendet der Convolutional Layer eine Reihe von Filtern auf unseren Buchstaben „D“ an. Beispielhaft wäre ein 3x3-Filter, der mögliche vertikale Kanten in unserem Objekt erkennt. Dann wird der Filter auf das Bild angewendet und führt eine elementweise Multiplikation zwischen dem Filter und dem zugrunde liegenden Bildausschnitt durch, gefolgt von einer Summierung der Ergebnisse. Diese Operation erzeugt dann eine Merkmalskarte (Feature Map), die nichts anderes als eine räumliche Darstellung der gelernten Merkmale ist.
Activation Function: Nach der Faltungsoperation aus dem Convolutional Layer wird eine Aktivierungsfunktion, wie beispielsweise die Rectified Linear Unit (ReLU) elementweise auf die Merkmalskarte angewendet. Dies führt Nichtlinearität ein, indem negative Werte durch 0 ersetzt werden, wodurch das Modell in der Lage ist, komplexere Muster zu lernen. Das Ergebnis wird als „aktivierte Merkmalskarte“ (activated feature map) bezeichnet.
Pooling Layer: Diese Schicht ist dafür verantwortlich, die räumlichen Dimensionen der Merkmalskarten zu reduzieren, wodurch das Netzwerk recheneffizienter und robuster gegenüber kleinen Variationen in der Eingabe wird. Zu den gängigen Pooling-Operationen gehören Max-Pooling (das Maximum eines lokalen Patches nehmen) und Average-Pooling (den Mittelwert eines lokalen Patches nehmen) Mit Patches sind übrigens kleine, rechteckige Ausschnitte aus einem größeren Bild oder einer Merkmalskarte gemeint. Zusammengefasst reduziert die Pooling-Schicht die räumlichen Dimensionen der aktivierten Merkmalskarte, was das Netzwerk recheneffizienter und robuster gegenüber Variationen in der Eingabe macht. Max-Pooling beispielsweise nimmt das Maximum aus einem lokalen Patch (z.B. 2x2 Pixel innerhalb der Merkmalskarte).
Repeat: Die Schritte 2–4 werden mehrfach wiederholt, wobei der Ausgang einer Schicht als Eingabe für die nächste Schicht dient. Jede nachfolgende Schicht lernt höherwertige Merkmale, wobei sie von einfachen Kanten zu komplexeren Mustern übergeht (z.B. Objektteile oder ganze Objekte). Die Abfolge von Faltungs-, Aktivierungs- und Pooling-Schichten wird mehrfach wiederholt. Mit jeder Schicht lernt das Netzwerk höherwertige Merkmale. Im Fall des Buchstabens „D“ könnten die ersten Schichten Kanten und Ecken erkennen, während spätere Schichten die gesamte Form des Buchstabens erkennen können.
Fully Connected Layer: Nach der letzten Pooling- oder Faltungsschicht (Convolutional Layer) wird eine vollständig verbundene Schicht (Fully Connected Layer) verwendet, um die gelernten Merkmale zu konsolidieren und die endgültige Ausgabe zu erzeugen. Diese Schicht flacht die 3D-Merkmalskarten zu einem 1D-Vektor ab, der dann in die Ausgabeschicht eingespeist wird.
Output Layer: Bei einer Zeichenerkennungsaufgabe könnte die Ausgabeschicht (Output Layer) so viele Neuronen haben, wie es Klassen gibt (z.B. 26 Neuronen für die Buchstaben des englischen Alphabets). Eine Softmax-Aktivierungsfunktion beispielsweise erzeugt Klassenwahrscheinlichkeiten, die anzeigen, wie wahrscheinlich es ist, dass das Eingabebild zu jeder Klasse gehört. Die Klasse mit der höchsten Wahrscheinlichkeit stellt die Vorhersage des Netzwerks dar, in unserem Fall den Buchstaben „D“.
Nun lass uns das mit Python ausprobieren: Für unser Skript werden wir die beliebte Machine-Learning-Bibliothek TensorFlow mit der Keras-API verwenden. Initialisiere zuerst am besten eine Python-Umgebung (venv) und erstelle dann das Skript mit den folgenden Imports:
import tensorflow as tf
from tensorflow.keras import layers, models
from tensorflow.keras.utils import to_categorical
Als nächstes verwenden wir ein sehr bekanntes Dataset für diese Aufgabe: EMNIST, das 124.800 Trainingsbilder und 20.800 Testbilder von handgeschriebenen Buchstaben enthält:
pip install emnist
Nun laden wir das Dataset in unser Skript und teilen es in Trainings- und Testsets auf:
from emnist import extract_training_samples, extract_test_samples
# Datensatz laden
train_images, train_labels = extract_training_samples('letters')
test_images, test_labels = extract_test_samples('letters')
Im nächsten Schritt werden wir unsere Daten vorverarbeiten, um sie optimal für unser Modell bereitzustellen. Zuerst werden wir unsere Trainingsbilder in einen 4D-Tensor umformen, der die Dimensionen (Anzahl der Proben, Höhe, Breite, Kanäle) hat. Dies ist erforderlich für die Eingabeform der Faltungsschicht (Convolutional Layer):
train_images = train_images.reshape((124800, 28, 28, 1))
Als nächstes werden wir den Datentyp der Trainingsbilder in float32 konvertieren und die Pixelwerte normalisieren, indem wir sie durch 255 teilen:
train_images = train_images.astype("float32") / 255
Wir wiederholen den gleichen Umformungsprozess für die Testbilder:
test_images = test_images.reshape((20800, 28, 28, 1))
test_images = test_images.astype("float32") / 255
Jetzt werden wir die Trainings- und Test-Labels in ein One-Hot-codiertes kategorisches Format konvertieren, indem wir die Funktion to_categorical verwenden:
train_labels = to_categorical(train_labels - 1)
test_labels = to_categorical(test_labels - 1)
Wir beginnen nun mit der CNN-Architektur, indem wir ein leeres sequenzielles Modell erstellen, das unsere CNN-Schichten enthält:
model = models.Sequential()
Des Weiteren fügen wir unsere erste Faltungsschicht (Convolutional Layer) mit 32 Filtern, einer 3x3-Kernelgröße, einer ReLU-Aktivierungsfunktion und einer Eingabeform von (28,28,1) hinzu:
model.add(layers.Conv2D(32, (3, 3), activation="relu", input_shape=(28, 28, 1))) # Convolutional Layer
Nun fügen wir eine Max-Pooling-Ebene mit einer Poolgröße von 2x2 hinzu, die die räumlichen Dimensionen der Merkmalskarten reduziert.
model.add(layers.MaxPooling2D((2, 2))) # Pooling Layer
Nun Fügen wir eine zweite Faltungsschicht (Convolutional Layer) mit 64 Filtern, einer Kernelgröße von 3x3 und einer ReLU-Aktivierungsfunktion sowie eine weitere Max-Pooling-Schicht mit einer Poolgröße von 2x2 hinzu, der eine weitere Faltungsschicht mit 64 Filtern und einer Kernelgröße von 3x3 folgt.
model.add(layers.Conv2D(64, (3, 3), activation="relu")) # Convolutional Layer
model.add(layers.MaxPooling2D((2, 2))) # Pooling Layer
model.add(layers.Conv2D(64, (3, 3), activation="relu")) # Convolutional Layer
Nun fügen wir einen Flatten-Layer hinzu, der die 3D-Merkmalskarten in ein 1D-Array umwandelt, das als Eingabe für den Fully-Connected-Layer verwendet werden kann.
model.add(layers.Flatten())
Nun Fügen wir eine vollständig verbundene Schicht mit 64 Knoten und einer ReLU-Aktivierungsfunktion hinzu.
model.add(layers.Dense(64, activation="relu"))
Schließlich wird die Ausgabeschicht mit 26 Neuronen, die den 26 Buchstabenklassen entsprechen, und einer Softmax-Aktivierungsfunktion hinzugefügt, um Wahrscheinlichkeitswerte für jede Klasse zu erzeugen.
model.add(layers.Dense(26, activation="softmax")) # Output Layer
Das ist die gesamte CNN-Architektur. Gratulation: Du hast dein erstes Convolutional Neural Network erstellt!
Aber was machen wir nun mit der Architektur? Wir müssen sie testen. So gehen wir vor: Zunächst kompilieren wir unser Modell mit dem Adam-Optimizer und der Funktion categorical_crossentropy. Außerdem legen wir die Metrik accuracy fest, um später die Leistungsfähigkeit des Modells bewerten zu können.
# Model kompilieren
model.compile(optimizer="adam", loss="categorical_crossentropy", metrics=["accuracy"])
Nun müssen wir unser Modell trainieren, es muss alles lernen, um später die richtigen Buchstaben entsprechend zu erkennen, wir geben ihm 5 Epochen und eine batch_size von 64.
model.fit(train_images, train_labels, epochs=5, batch_size=64)
Jetzt können wir unser Modell auswerten und Inferenztests damit durchführen. Das heißt, wir können unsere eigenen Buchstaben auf ein Stück Papier schreiben, ein Bild davon machen und überprüfen, ob unser trainiertes Modell sie erkennen kann:
test_loss, test_acc = model.evaluate(test_images, test_labels)
print(f"Test accuracy: {test_acc}")
Und das war's! Ich hoffe, dieser Artikel hat Dir ein klareres Verständnis dafür vermittelt, wie ein CNN funktioniert und wie Du es selbst implementieren kannst.